Today I’ll talk about the concept of table buffers on SAP. This topic is pretty interesting and gives certain implications on ABAP programming model. I think it’s really useful to the functional consultants to have certain amount of knowledge on this subject.
As we all know, a well developed ERP system should try to optimize its performance by using every possible way. Especially the response time it takes to process the requests from the business user should be minimize as much as possible. By taking this factor into consideration SAP has designed the concept called ‘Table buffer’.
This concept has been developed by considering two main factors.
1. The network traffic between the application server and the database server
As I explained on my earlier posts the SAP database server and the application server can be located on two different physical servers. So every time the application server requests some data from the database, it should be transferred through the network from the database server to the application server which may lead to high network traffic on a typical SAP installation where multiple requests will be passed per second. This factor would slow down the system.
2. The database load
When the programs processed by the application server, directly deal with the tables on the database to manage the data, it increases the database load which will slow down the database’s performance. This will affect a program which uses a specific table in the database as well as other programs which try to use some different tables in the same database.
Solution for the issue
The concept of table buffer simply load the data of a database table into the application server’s RAM. So the programs would access the data from the application server’s RAM rather than directly from the database table.
By buffering data, we increase performance in two important ways:
1.The programs using the buffered data run faster because they don't have to wait for it to come from the database. This reduces delays waiting for the database and the network that connects it.
2.The other programs that need to access the database run faster because there is less load on the database and less traffic on the network.
According to the benchmark tests, buffering a table can cause a select statement to run 10 to 100 times faster or more.
The next question that SAP had was, whether to allow all the tables to be buffered or not. Obviously we all would say ‘Yes’. However, buffers are stored entirely on RAM, so space is limited by the amount of RAM available. In fact, there is so much more data than there is RAM, that tables must be buffered with caution to prevent overruns. If a buffer overruns, it might swap to disk, which can eradicate any performance gained by buffering. So SAP has developed this concept in such a way that each individual table can be configured to be buffered or not. But the tables containing a numeric data type as the primary key cannot be buffered
Buffering can be activated through the technical settings of any table. The following screenshot shows table T001, which has been activated to be buffered.

How does this concept work?
When an ABAP program issues an open sql statement, the application server will first check whether the table has been activated to be buffered or not, if the table has been activated to be buffered, the server will check the RAM for the buffered data.
If the buffer is available, the program will read the data from the RAM else it will read it from the database, populate the buffer and subsequently read from the buffer.
I think this post should have given you a basic idea about the table buffers. Definitely this concept improves the performance of the system, but we have to take certain facts into consideration when we try to activate the table buffer on any table. On my next post I will talk about the implications of table buffers in a more detailed way. As well as I will take a look at the multi application server environment and the table buffers.
Please send me your comments.

 In addition, Data dictionary works like a remote control to the actual database. Developers create the database objects on the data dictionary and activate them; in the background the system will automatically generate the corresponding SQL statements and create the objects on the actual database.
In addition, Data dictionary works like a remote control to the actual database. Developers create the database objects on the data dictionary and activate them; in the background the system will automatically generate the corresponding SQL statements and create the objects on the actual database. 



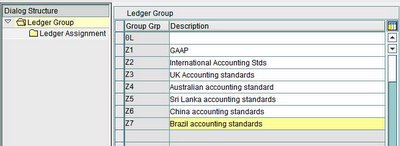
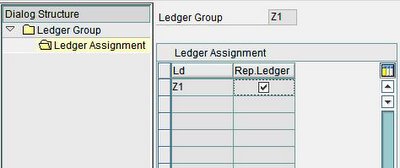



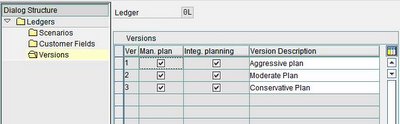

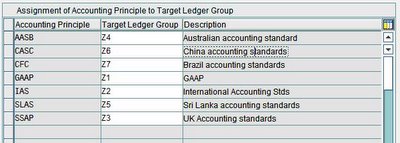




 2. SAP distribution presentation configuration: the application and database servers are combined on one computer and the presentation servers run separately. This is used for smaller systems, and is often seen on a development system.
2. SAP distribution presentation configuration: the application and database servers are combined on one computer and the presentation servers run separately. This is used for smaller systems, and is often seen on a development system. 3. SAP two-tier client/server configuration: the presentation and application servers are combined and the database server is separate. This configuration is used in conjunction with other application servers. It is used for a batch server when the batch is segregated from the online servers. A SAPGUI is installed on it to provide local control.
3. SAP two-tier client/server configuration: the presentation and application servers are combined and the database server is separate. This configuration is used in conjunction with other application servers. It is used for a batch server when the batch is segregated from the online servers. A SAPGUI is installed on it to provide local control.


